


Semantic MapNet: Building Allocentric Semantic Maps and Representations from Egocentric Views
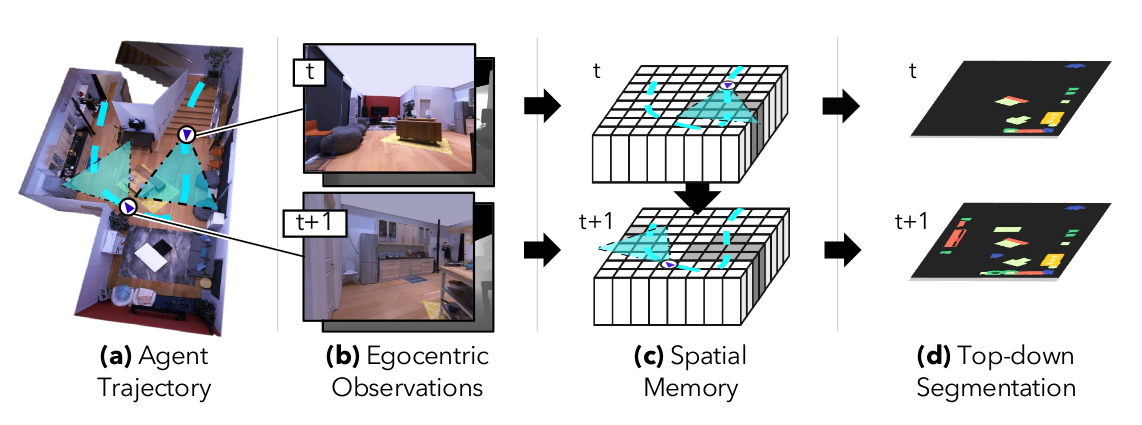
We study the task of semantic mapping – specifically, an embodied agent (a robot
or an egocentric AI assistant) is given a tour of a new environment and asked to
build an allocentric top-down semantic map (‘what is where?’) from egocentric
observations of an RGB-D camera with known pose (via localization sensors).
Importantly, our goal is to build neural episodic memories and spatio-semantic
representations of 3D spaces that enable the agent to easily learn subsequent tasks
in the same space – navigating to objects seen during the tour (‘Find chair’) or
answering questions about the space (‘How many chairs did you see in the house?’).
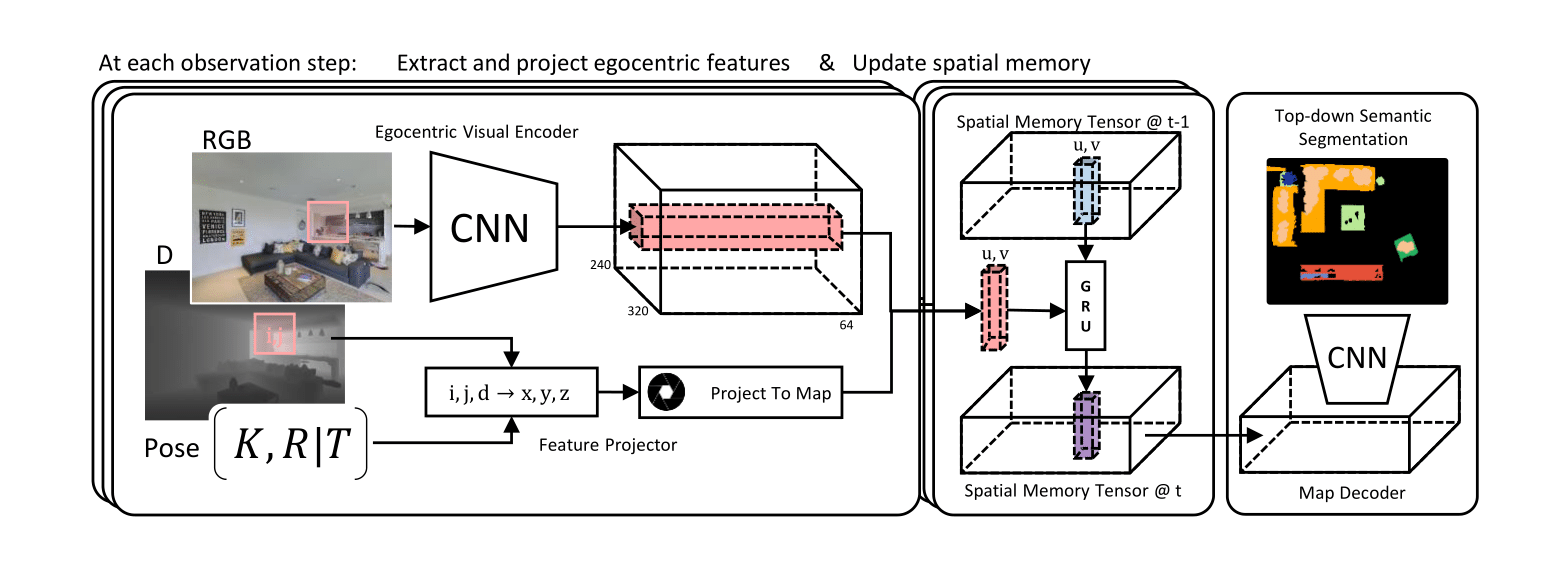
Towards this goal, we present Semantic MapNet (SMNet), which consists of:
(1) an Egocentric Visual Encoder that encodes each egocentric RGB-D frame,
(2) a Feature Projector that projects egocentric features to appropriate locations
on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length × width ×
feature-dims that learns to accumulate projected egocentric features, and (4) a Map
Decoder that uses the memory tensor to produce semantic top-down maps.
SMNet combines the strengths of (known) projective camera geometry and neural
representation learning. On the task of semantic mapping in the Matterport3D
dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover,
we show how to use the spatio-semantic allocentric representations build by SMNet
for the task of ObjectNav and Embodied Question Answering.
Semantic MapNet: Building Allocentric Semantic Maps and Representations from Egocentric Views
Press Coverage



People





